一文講透DataOps數(shù)據(jù)運營 從數(shù)據(jù)采集出發(fā),構(gòu)建敏捷高效的數(shù)據(jù)價值鏈
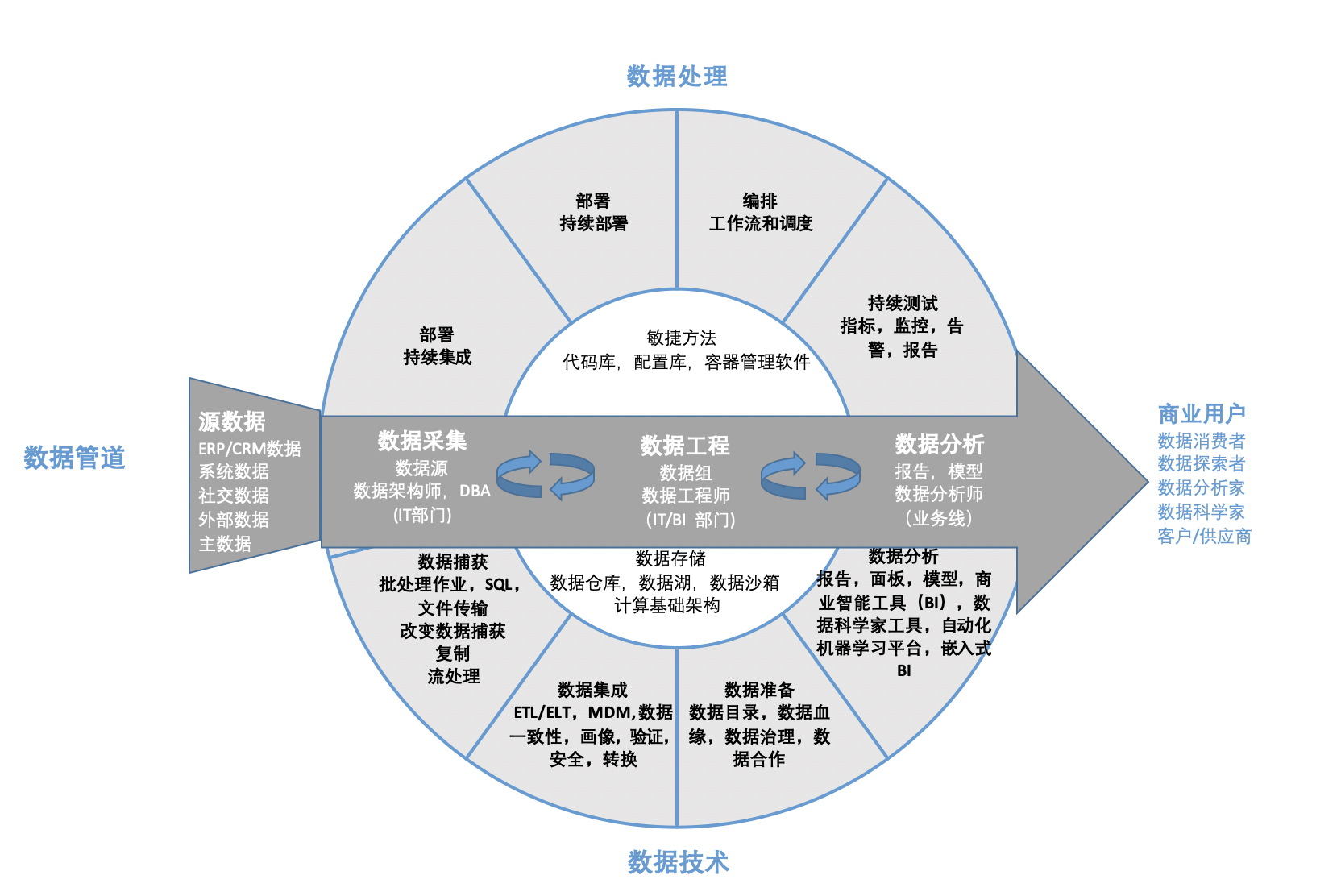
在數(shù)據(jù)驅(qū)動的時代,企業(yè)紛紛尋求更高效、更可靠的數(shù)據(jù)管理方法來支撐決策與創(chuàng)新。DataOps 應運而生,它并非一個單一的工具或平臺,而是一種集文化、流程與技術(shù)于一體的協(xié)同方法論,旨在優(yōu)化數(shù)據(jù)從產(chǎn)生到消費的全生命周期管理,縮短數(shù)據(jù)價值實現(xiàn)的周期,提升數(shù)據(jù)質(zhì)量和團隊協(xié)作效率。簡單來說,DataOps 是將敏捷開發(fā)、DevOps理念與數(shù)據(jù)工程、數(shù)據(jù)治理深度結(jié)合,讓數(shù)據(jù)運營像軟件交付一樣快速、可靠且可重復。
核心目標:打造敏捷、高質(zhì)量的數(shù)據(jù)流水線
DataOps 的核心目標是打破傳統(tǒng)數(shù)據(jù)管理中的孤島、延遲和質(zhì)量不一等問題。它強調(diào):
- 敏捷與協(xié)作:促進數(shù)據(jù)生產(chǎn)者、工程師、分析師和業(yè)務(wù)用戶之間的無縫協(xié)作,快速響應業(yè)務(wù)需求變化。
- 自動化與效率:通過自動化工具鏈,減少手動、重復性工作,加速數(shù)據(jù)從原始狀態(tài)到可用洞察的流程。
- 質(zhì)量與可信度:將數(shù)據(jù)質(zhì)量監(jiān)控、測試和治理內(nèi)嵌到流程的每一個環(huán)節(jié),確保數(shù)據(jù)產(chǎn)出的準確性與一致性。
- 可觀測性與監(jiān)控:對整個數(shù)據(jù)流水線的健康度、性能和產(chǎn)出進行實時監(jiān)控與度量。
而這一切的起點和基石,正是數(shù)據(jù)采集。
基石與起點:數(shù)據(jù)采集在DataOps中的關(guān)鍵角色
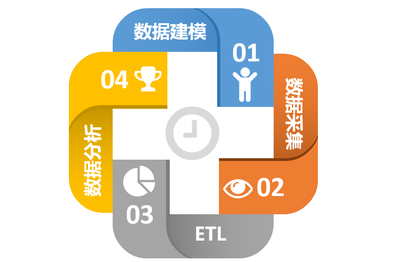
數(shù)據(jù)采集是DataOps數(shù)據(jù)流水線的“源頭活水”。它的目標不僅是“拿到數(shù)據(jù)”,更是要以一種支持后續(xù)敏捷、自動化運營的方式,高效、可靠地獲取數(shù)據(jù)。在DataOps框架下,數(shù)據(jù)采集被賦予了新的要求和內(nèi)涵。
1. 采集范圍:全面覆蓋多源異構(gòu)數(shù)據(jù)
現(xiàn)代企業(yè)的數(shù)據(jù)來源極其豐富,DataOps要求采集系統(tǒng)具備強大的連通性:
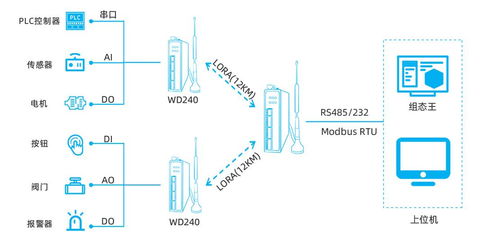
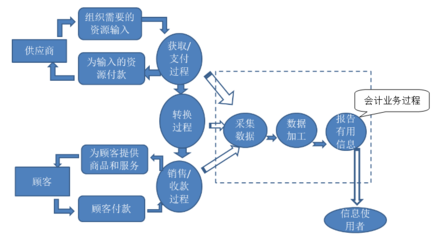
- 業(yè)務(wù)數(shù)據(jù)庫:通過CDC(變更數(shù)據(jù)捕獲)、增量同步等技術(shù)實時或準實時獲取交易數(shù)據(jù)。
- 日志與事件流:應用程序日志、用戶行為事件、服務(wù)器日志等,通常通過消息隊列(如Kafka)或日志采集代理(如Fluentd, Logstash)實時接入。
- 外部API:第三方平臺數(shù)據(jù)、公開數(shù)據(jù)、合作伙伴數(shù)據(jù)等。
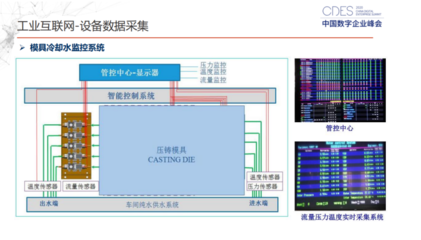
- 物聯(lián)網(wǎng)與傳感器數(shù)據(jù):時序數(shù)據(jù)流。
- 文件與對象存儲:CSV、Excel、Parquet等格式的批量文件。
2. 核心原則:為運營而設(shè)計
DataOps視角下的數(shù)據(jù)采集,遵循以下原則:
- 可配置與可復用:采集任務(wù)應通過配置而非硬編碼實現(xiàn),便于快速調(diào)整和復用,響應新的數(shù)據(jù)源需求。
- 元數(shù)據(jù)驅(qū)動:在采集階段即開始捕獲數(shù)據(jù)源的業(yè)務(wù)和技術(shù)元數(shù)據(jù)(如schema、更新頻率、負責人),為后續(xù)的數(shù)據(jù)發(fā)現(xiàn)、血緣分析和治理奠定基礎(chǔ)。
- 質(zhì)量前置:在數(shù)據(jù)入口處實施基礎(chǔ)的校驗(如非空檢查、格式檢查),并打上數(shù)據(jù)質(zhì)量標簽,防止“臟數(shù)據(jù)”污染下游流水線。
- 可靠性與容錯:具備斷點續(xù)傳、錯誤重試、死信隊列等機制,確保數(shù)據(jù)不丟失。
- 輕量且可觀測:采集過程本身應被監(jiān)控,產(chǎn)出清晰的日志和指標(如采集速率、延遲、錯誤數(shù)),便于運營團隊快速定位問題。
3. 技術(shù)實現(xiàn):自動化與協(xié)同的工具鏈
DataOps鼓勵采用現(xiàn)代化、自動化的工具來支撐采集流程:
- 數(shù)據(jù)集成平臺/工具:如Airbyte、Fivetran、StreamSets等,提供低代碼/無代碼的連接器配置,簡化多源對接。
- 流處理框架:如Apache Kafka(作為中樞消息總線)、Apache Flink、Spark Streaming用于實時流數(shù)據(jù)的攝取與初步處理。
- 基礎(chǔ)設(shè)施即代碼:使用Terraform、Ansible等工具定義和版本化采集任務(wù)所需的基礎(chǔ)設(shè)施(如虛擬機、容器),確保環(huán)境一致性。
- 流水線編排:將采集任務(wù)作為數(shù)據(jù)流水線的第一個可編排步驟,集成到如Apache Airflow、Prefect、Dagster等編排工具中,實現(xiàn)任務(wù)調(diào)度、依賴管理和自動化執(zhí)行。
從采集到價值:DataOps的完整閉環(huán)
數(shù)據(jù)采集只是第一步。在DataOps中,采集來的數(shù)據(jù)立即進入一個高度自動化、協(xié)同的流水線:
- 自動化入湖/入倉:數(shù)據(jù)被可靠地送入數(shù)據(jù)湖或數(shù)據(jù)倉庫的原始層。
- 持續(xù)集成與持續(xù)交付:數(shù)據(jù)轉(zhuǎn)換、清洗、建模的代碼(如SQL、Python腳本)像應用程序代碼一樣,通過版本控制(Git)、自動化測試、代碼評審后,被自動部署到生產(chǎn)環(huán)境。
- 內(nèi)嵌的質(zhì)量監(jiān)控:在流水線的關(guān)鍵節(jié)點自動運行數(shù)據(jù)質(zhì)量測試(如值域驗證、唯一性檢查、一致性校驗),失敗則觸發(fā)告警或阻斷流程。
- 自助服務(wù)與消費:經(jīng)過處理的高質(zhì)量數(shù)據(jù),通過數(shù)據(jù)目錄、API或分析工具,安全、便捷地提供給業(yè)務(wù)用戶和分析師使用。
- 反饋與優(yōu)化:業(yè)務(wù)用戶的使用反饋和數(shù)據(jù)質(zhì)量問題的根本原因分析,會反過來驅(qū)動采集策略、處理邏輯和流水線的優(yōu)化,形成一個持續(xù)改進的閉環(huán)。
###
DataOps數(shù)據(jù)運營是一種致力于讓數(shù)據(jù)工作流現(xiàn)代化、工業(yè)化和敏捷化的哲學與實踐。數(shù)據(jù)采集作為其源頭環(huán)節(jié),已從傳統(tǒng)的“一次性搬運”演變?yōu)橐粋€可配置、可觀測、質(zhì)量內(nèi)嵌的自動化過程。它確保了高質(zhì)量、可靠的數(shù)據(jù)能源源不斷地流入后續(xù)的價值創(chuàng)造流程。理解并踐行以DataOps理念重塑的數(shù)據(jù)采集乃至整個數(shù)據(jù)生命周期管理,是企業(yè)構(gòu)建數(shù)據(jù)驅(qū)動能力、在數(shù)字競爭中贏得先機的關(guān)鍵一步。它最終實現(xiàn)的,是一個高效、可信、能快速響應業(yè)務(wù)需求的數(shù)據(jù)供應鏈。
因此,DataOps不僅僅是技術(shù)或工具,它更是一場關(guān)于如何以運營思維管理和消費數(shù)據(jù)的文化變革。從精心設(shè)計的數(shù)據(jù)采集開始,每一步都朝著更敏捷、更可靠、更協(xié)同的目標邁進。
如若轉(zhuǎn)載,請注明出處:http://www.2weima.cn/product/59.html
更新時間:2026-02-21 17:37:48